
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 부트캠프
- 미뮤엔토 에디터
- 현혹
- 정년이
- 이지스퍼블리싱
- 데이터분석취업
- 데이터분석부트캠프
- 데이터분석
- 대외활동
- BDA
- 드라마
- 재혼황후
- 데이터분석가
- 국비지원
- 미유엔토
- 패스트캠퍼스데이터분석부트캠프
- 지금 우리 학교는
- 이태원 클라쓰
- 대외활동 추천
- 웹툰 원작
- 패스트캠퍼스부트캠프
- DOIT!
- 미디어 콘텐츠
- 딥러닝교과서
- 유미의 세포들
- 대중문화
- 패스트캠퍼스
- 딥러닝 스터디
- 국비지원취업
- 미뮤엔토
- Today
- Total
디지털 마케팅 LAB
BDA X 이지퍼블리싱 스터디 (3주차) 본문
1. 날씨 시계열 예측
막스 플랑크 생물 지구화학 연구소에서 기록한 날씨 시계열 데이터셋을 사용해서 시계열 데이터를 분석해보고 미래의 날씨를 예측한다.
데이터

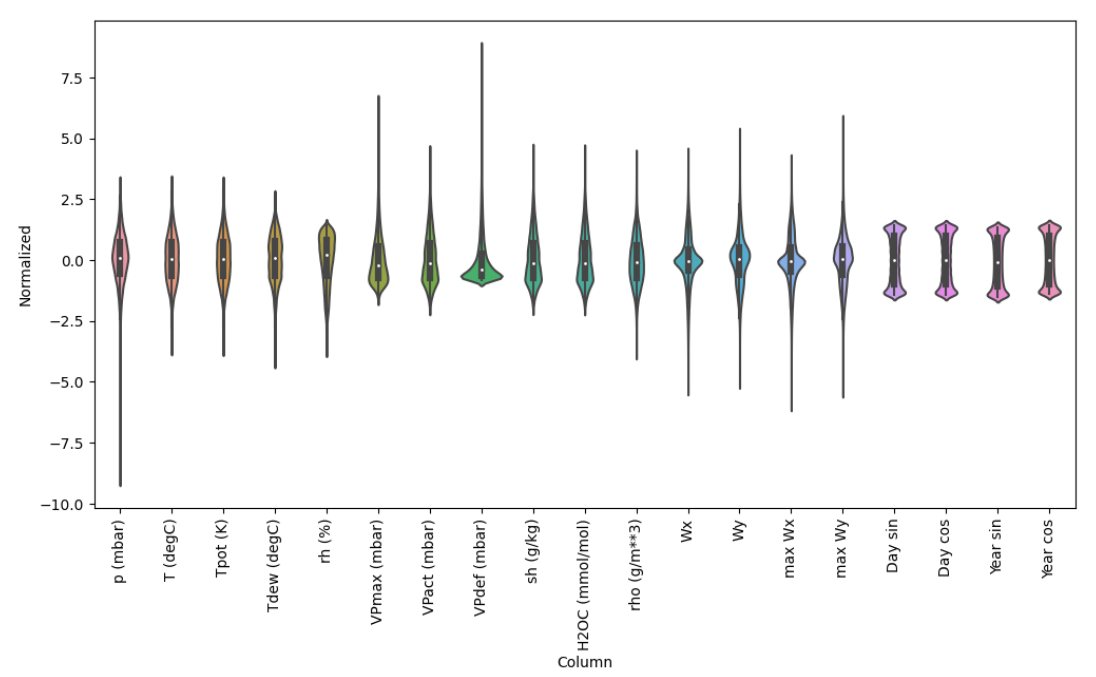
온도, 대기압, 습도 등 14가지 feature로 이루어져있다.
10분 간격으로 되어있던 데이터를 step 6으로 슬라이싱하여 1시간 간격으로 바꿔준다.
검사 및 정리

풍속의 min이 -9999로 나온 것을 오류로 생각하여 0으로 교체
특성 엔지니어링
- 풍향과 속도 열을 바람 벡터로 변환한다.
- 사인 및 코사인 변환을 사용하여 시간 및 시간 신호를 지워 사용가능한 신호를 얻는다.
- 고속 푸리에 변환을 사용하여 특성을 추출하여 중요한 빈도를 결정한다.
데이터 분할 및 정규화
훈련, 검증 및 테스트 데이터 세트를 (70%, 20%, 10%)로 분할한다.
신경망을 훈련하기 전에 특성의 크기를 정하는 것이 중요하다. 정규화는 평균을 빼고 각 특성의 표준 편차로 나누어 크기 조정을 수행하는 일반적인 방법이다.
데이터 창 작업
작업 및 모델 유형에 따라 다양한 데이터 창을 생성할 수 있다. 예를 들어,

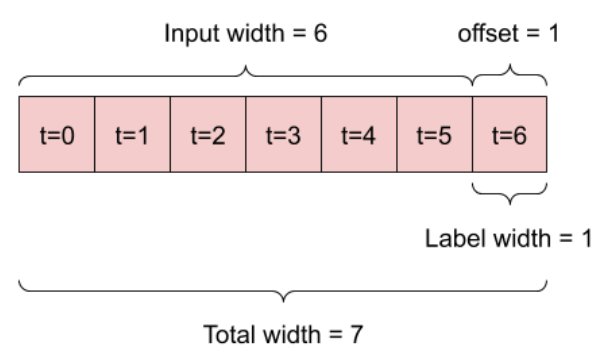
나머지 부분에서는 WindowGenerator 클래스를 정의한다. 이 클래스는 다음을 수행할 수 있다.
- 위의 다이어그램과 같이 인덱스와 오프셋을 처리한다.
- 특성 창을 (features, labels) 쌍으로 분할한다.
- 결과 창의 내용을 플롯한다.
- tf.data.Dataset를 사용하여 훈련, 평가 및 테스트 데이터로부터 이러한 창을 여러 배치로 효율적으로 생성한다.
단일 스텝 모델
이러한 종류의 데이터를 기반으로 빌드할 수 있는 가장 간단한 모델은 현재 조건만을 기초로 1 타임스텝(1시간) 후의 단일 특성 값을 예측하는 모델이다.
따라서 1시간 미래의 T (degC) 값을 예측하는 모델을 빌드하는 것으로 시작한다.

다음과 같은 단일 스텝 (input, label) 쌍을 생성하도록 WindowGenerator 객체를 구성한다.
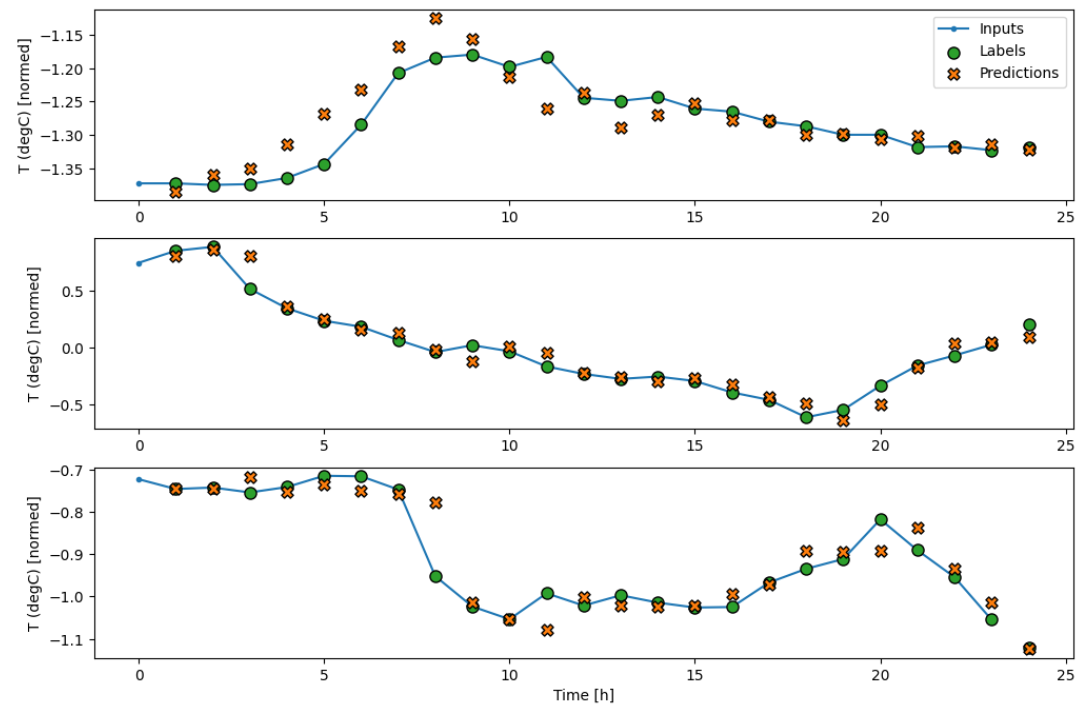
예측 비교

성능 비교
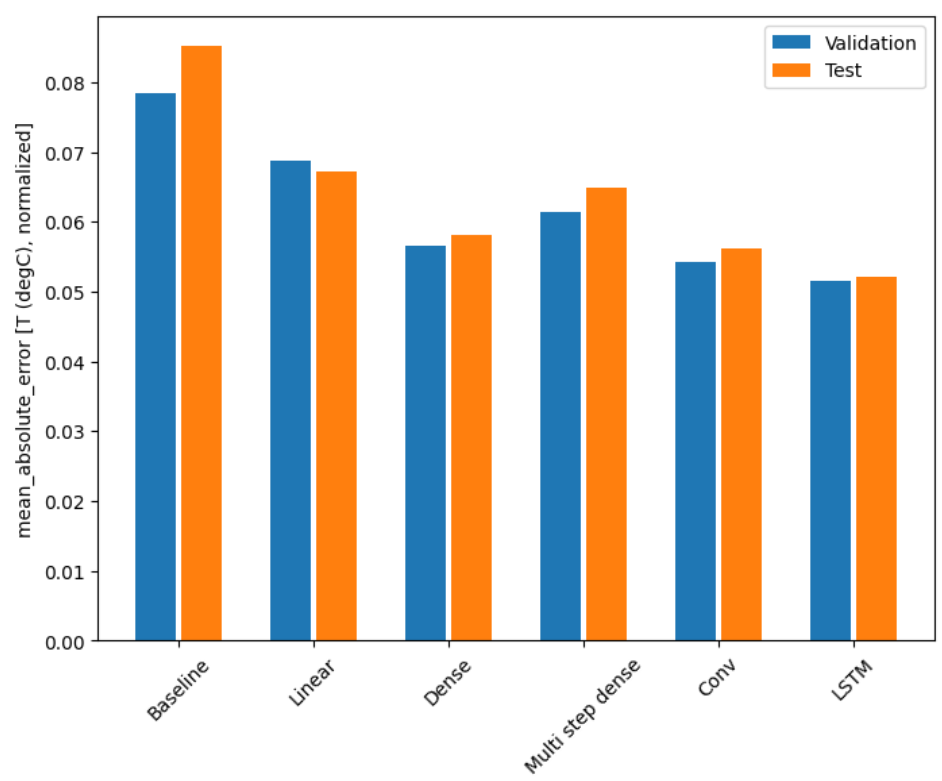
대체적으로 이전 모델보다 성능이 좋아지는 것을 확인할 수 있다.
2. 순환 신경망을 활용한 셰익스피어의 문자열 생성
셰익스피어 데이터셋을 이용해서 셰익스피어풍의 작품을 생성하는 순환신경망을 만들어본다. 생성된 문장은 의미를 해석하기는 어렵지만 언뜻 보기에는 자연스러운 문장으로 보일 것이다.
- 문자 기반 순환 신경망
- 데이터 셋에서 문자 시퀀스 ("Shakespear")가 주어지면, 시퀀스의 다음 문자("e")를 예측하는 모델을 훈련
- 모델은 작은 텍스트 배치(각 100자)로 훈련되었으며, 모델을 반복하여 호출하면 더 긴 텍스트 시퀀스 생성이 가능
데이터
케라스에서 데이터 파일을 불러와 파이썬과 호환되도록 디코딩 후에 사용한다.
텍스트 길이는 1115394자이고, 고유 문자수는 '\n', ' ', '!', '$', '&', "'", ',', '-', '.', '3', ':', ';', '?' 부터 대문자 알파벳과 소문자 알파벳까지 총 65개이다.
텍스트 전처리
1) 텍스트 벡터화
- 문자들을 수치화
- 두 개의 조회 테이블(lookup table)을 만들어 하나는 문자를 숫자에 매핑하고 다른 하나는 숫자를 문자에 매핑

2) 훈련 샘플과 target 만들기
- 모델의 입력은 문자열 시퀀스가 될 것이고, 모델을 훈련시켜 출력을 예측
- 출력 = 현재 타임 스텝(time step)의 다음 문자
- 각 입력 시퀀스에서, 해당 타깃은 한 문자를 오른쪽으로 이동한 것을 제외하고는 동일한 길이의 텍스트를 포함 -> 텍스트를 시퀀스 길이 + 1개의 청크(chunk)로 나눈다
ex) seq_length=4, 텍스트="Hello" -> 입력 시퀀스는 "Hell"이고 타깃 시퀀스는 "ello" -> 텍스트를 시퀀스 길이 + 1개의 청크(chunk)로 나눈다


3) 훈련 배치 생성
모델 설계
- tf.keras.layers.Embedding : 입력층, embedding_dim 차원 벡터에 각 문자의 정수 코드를 매핑하는 훈련 가능한 검색 테이블
- f.keras.layers.GRU : 크기가 units = rnn_units인 RNN의 유형
- tf.keras.layers.Dense : 크기가 vocab_size인 출력을 생성하는 출력층
각 문자에 대해 모델은 임베딩을 검색하고, 임베딩을 입력으로 하여 LSTM을 1개의 타임 스텝으로 실행하고, 완전연결층을 적용하여 다음 문자의 로그 가능도(log-likelihood)를 예측하는 로짓을 생성
텍스트 생성

'BDA 딥러닝 easystudy' 카테고리의 다른 글
| BDA X 이지퍼블리싱 스터디 (4주차) (1) | 2023.06.06 |
|---|---|
| BDA X 이지퍼블리싱 스터디 (1주차) (0) | 2023.05.15 |
