
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- 이지스퍼블리싱
- 재혼황후
- 국비지원
- 유미의 세포들
- 대중문화
- 부트캠프
- 딥러닝교과서
- 이태원 클라쓰
- 미유엔토
- 데이터분석취업
- 패스트캠퍼스부트캠프
- 현혹
- 딥러닝 스터디
- 데이터분석가
- 대외활동
- 미뮤엔토
- 웹툰 원작
- 드라마
- 대외활동 추천
- 데이터분석부트캠프
- 미디어 콘텐츠
- 데이터분석
- 패스트캠퍼스데이터분석부트캠프
- 정년이
- BDA
- 지금 우리 학교는
- 패스트캠퍼스
- DOIT!
- 미뮤엔토 에디터
- 국비지원취업
Archives
- Today
- Total
디지털 마케팅 LAB
패스트캠퍼스 데이터분석 부트캠프 4주차_PYTHON (2) 본문
데이터 가공
- 인덱스
- 인덱스 변경
■ 인덱스 몇개를 바꿀 때 - 데이터명.rename({기존 인덱스: 바꿀 인덱스, 기존 인덱스: 바꿀 인덱스, ...})
■ 인덱스 전체를 바꿀 때 - 데이터명.index = 바꿀 인덱스 리스트 - 열을 인덱스로 설정
■ 데이터명.set_index(컬럼명) - 인덱스를 열로 변환
■ 데이터명.reset_index()
■ 만약 열로 변환된 인덱스를 삭제하고 싶다면 'drop=True' 옵션 추가 ( = 인덱스가 새로 리셋된 결과)
- 인덱스 변경
- 행
- 행 추가
■ pd.concat([기존 데이터명, 추가할 데이터명])df3 = pd.concat([df1, df2])df3 = df3.reset_index(drop=True)df3 - 행 제거
■ 데이터명.drop(제거할 인덱스 명)
■ 데이터명.drop([제거할 인덱스 범위]) - 행 중복 제거
■ 데이터명.drop_duplicates()
- 행 추가
- 열
- 열 추가
■ 데이터명[추가할 컬럼] = 추가할 값 리스트 or 시리즈 - 열 제거
■ 데이터명.drop(제거할 컬럼, axis=1) - 열 이름 변경
■ 이름 하나를 바꿀 때 - 데이터명.rename({기존 열 이름: 바꿀 이름, 기존 열 이름 : 바꿀 이름, ...})
■ 이름 전체를 바꿀 때 - 데이터명.columns = 열 이름 리스트
- 열 추가
- 결측값 처리
- 결측값 확인
■ isna(): 결측값을 True로 반환
■ notna(): 결측값을 False로 반환 - 결측값 제거
■ 데이터명.dropna(axis=0, how='any', subset=None)
■ axis: {0: index / 1: columns}
■ how: {'any' : 존재하면 제거 / 'all' : 모두 결측치면 제거}
■ subset: 행/열의 이름을 지정 → 지정된 행/열에서의 결측값 확인 - 결측값 대치
■ 데이터 전체 - 데이터명.fillna(대치할 값)
■ 특정 컬럼 - 컬럼.fillna(대치할 값)
■ 결측값 바로 위의 값으로 - 데이터명.fillna(method='ffill')
■ 결측값 바로 아래의 값으로 - 데이터명.fillna(method='bfill')
- 결측값 확인
- 타입 변환
- 컬럼.astype(타입)
- 날짜 다루기
- 문자형을 날짜형으로 변경
■ pd.to_datetime(컬럼, format='날짜 형식')
형식 설명 %Y 0을 채운 4자리 연도 %y 0을 채운 2자리 연도 %m 0을 채운 월 %d 0을 채운 일 %H 0을 채운 시간 %M 0을 채운 분 %S 0을 채운 초 - 날짜를 원하는 형식으로 변경
■ 컬럼.dt.strftime('날짜 형식') - dt 연산자 변경
■ 컬럼.dt.연산자연산자 설명 year 연도 month 월 day 일 dayofweek 요일(0-월요일, 6-일요일) day_name() 요일을 문자열로 - 날짜 계산
■ day 연산: pd.Timedelta(days=숫자)df['minus day1'] = df['Date1'] - pd.Timedelta(days=1) # 하루 전 날짜df['plus day7'] = df['Date1'] + pd.Timedelta(days=7) # 일주일 후 날짜
■ month 연산: pd.DateOffset(months=숫자)# month, year 연산을 위해서 offset라이브러리 설치 필요from pandas.tseries.offsets import DateOffset
df['plus month1'] = df['Date1'] + DateOffset(months=1) # 한달 후 날짜df['minus month3'] = df['Date1'] - DateOffset(months=3) # 세달 전 날짜
■ year 연산: pd.DateOffset(years=숫자)df['plus year1'] = df['Date1'] + DateOffset(years=1) # 일년 후 날짜df['minus year3'] = df['Date1'] + DateOffset(years=1) # 삼년 전 날짜 - 날짜 구간 데이터 만들기
■ pd.date_range(start=시작일자, end=종료일자, periods=기간수, freq='주기')주기 형식 설명 D 일별 W 주별 M 월별 말일 MS 월별 시작일 A 연도별 말일 AS 연도별 시작일 - 기간 이동 계산
■ 컬럼.rolling().집계함수()# 7일 이동평균## 지난 7일간의 평균을 구하는 것이기 때문에 1~6일까지의 'ma7' 컬럼은 결측값df1['ma7'] = df1['Temp'].rolling(7).mean() - 행 이동
■ 컬럼.shift(이동할 행의 수)
■ 전날 대비 변화율이 얼마나 되는지 구할 때 많이 사용df2['Temp shift1'] = df2['Temp'].shift(1) # 'temp' 컬럼에서 한개씩 밀린 값을 'shift1'컬럼으로 = 전날의 기온df2['pct change'] = (df2['Temp shift1'] - df2['Temp'])/df2['Temp'] # 전일대비 기온 변화율df2['Temp'].shift(-1).head(10) # 음수를 넣으면 다음칸의 값을 앞으로 당겨온다. ex) 다음날의 기온
- 문자형을 날짜형으로 변경
- 고급 기능
- apply 함수
■ 사용자 정의 함수를 데이터에 적용하고 싶을 때 사용
■ 데이터명.apply(함수, axis=0/1)# 예시1## 함수가 열을 참조했기 때문에 axis=1 적용def pclass_sibsp(x):if x['Pclass'] == 1 and x['SibSp'] == 1:return 1else:return 0df1['pclass_sibsp_filter'] = df1.apply(pclass_sibsp, axis=1)# 예시2def adult(x):if x >= 19:return 1elif x < 19:return 0else:return np.nandf1['adult_yn'] = df1['Age'].apply(adult)
■ 간단한 함수는 lambda로 구현 가능# 예시1과 같은 함수df1['pclass_sibsp_lambda'] = df1.apply(lambda x: 1 if x['Pclass'] == 1 and x['SibSp'] == 1 else 0, axis=1) - map 함수
■ 값을 특정 값으로 치환하고 싶을 때 사용
■ 컬럼.map(매핑 딕셔너리)gender_map = {'male':'남자', 'female':'여자'}df1['Sex_kr'] = df1['Sex'].map(gender_map) - 문자열 함수
메소드 설명 컬럼.str.contains(문자열) 문자열을 포함하고 있는지 유무 컬럼.str.replace(기존문자열, 대치문자열) 문자열 대치 컬럼.str.split(문자열, expand=True/False, n=개수) 특정 문자열을 기준으로 쪼개기 컬럼.str.lower() 소문자로 바꾸기 컬럼.str.upper() 대문자로 바꾸기
- apply 함수
- 데이터 결합
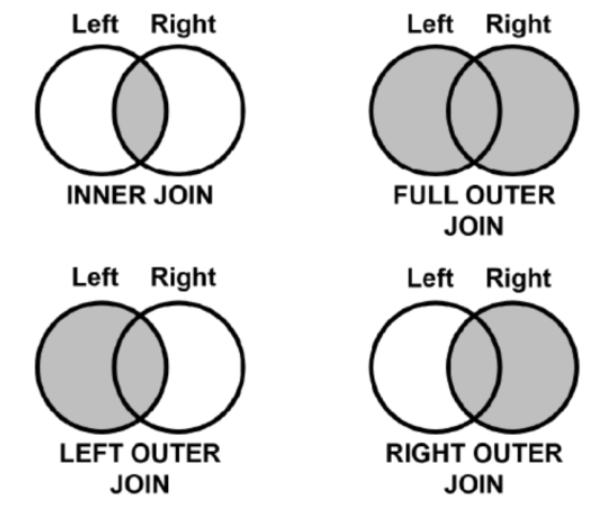
- pd.merge(데이터1, 데이터2, on='기준컬럼', how='결합방법')
■ 결합 방법에는 4가지가 있다 → 'inner', 'left', 'right', 'outer' - 두 데이터의 기준 컬럼명이 다를 경우
■ pd.merge(데이터1, 데이터2, left_on='데이터1의 기준컬럼', right_on='데이터2의 기준컬럼', how='결합방법')
- pd.merge(데이터1, 데이터2, on='기준컬럼', how='결합방법')
데이터 집계
- 분포 및 요약 통계
- describe(): 컬럼별 값의 갯수, 평균, 표준편차, 최솟값, 최댓값, 사분위수를 보여준다.
- 대푯값
- 결측값이나 숫자형이 아닌 데이터가 섞인 경우 'numeric_only=True' 옵션 적용
메소드 설명 min() 최솟값 max() 최댓값 mean() 평균 median() 중간값 std() 표준편차 var() 분산 quantile() 분위수
- 결측값이나 숫자형이 아닌 데이터가 섞인 경우 'numeric_only=True' 옵션 적용
- 변수의 상관관계
- 상관관계 분석은 두 변수의 관련성을 구하는 분석
- 두 변수 간의 연관된 정도이지 인과관계를 설명하지 않는다.
- 상관계수 = 두 변수가 함께 변하는 정도 / 두 변수가 각각 변하는 정도

- 그룹화
- 같은 값을 한 그룹으로 묶어서 여러 가지 연산 및 통계를 구할 수 있다.
- 데이터명.groupby(컬럼).연산및통계함수
- 단일 그룹화
함수 설명 count() 행의 갯수 nunique() 행의 유니크한 갯수 sum() 합 mean() 평균 min() 최솟값 max() 최댓값 std() 표준편차 var() 분산 - 다중 그룹화
# 성별과 객실 등급을 기준으로 그룹으로 묶고 다음 컬럼들의 평균, 최소, 최대값을 일괄적으로 계산df.groupby(['Sex','Pclass'])[['Survived','Age','SibSp','Parch','Fare']].aggregate([np.mean, np.min, np.max])

데이터 재구조화
- crosstab
- 범주형 데이터를 비교분석할 대 유용
- 범주별 갯수 구하기
■ pd.crosstab(행으로 넣을 컬럼, 열로 넣을 컬럼) - 범주별 비율 구하기
■ normalize='all' 옵션은 전체 비율의 합이 100%임을 의미
■ normalize='index' 옵션은 행별 합이 100%임을 의미
■ normalize='columns' 옵션은 열별 합이 100%임을 의미
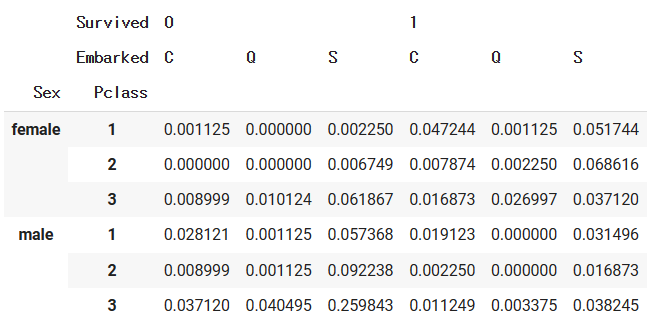
■ margins=True 옵션은 행별/열별 합계를 보여줌 - 다중 인덱스, 다중 컬럼의 범주표 구하기
pd.crosstab(index=[df['Sex'], df['Pclass']], columns=[df['Survived'], df['Embarked']], normalize='all')
- 피벗테이블
- 엑셀의 피벗테이블처럼 인덱스별 컬럼별 값의 연산을 할 수 있다.
- 단일 인덱스, 단일 컬럼, 단일 값
■ margins 옵션을 통해 행과 열 전체의 값도 구할 수 있다.# 성별을 인덱스로, 객실등급을 컬럼으로, 평균 생존율을 값으로 갖는 피벗테이블 생성pd.pivot_table(df, index='Sex', columns='Pclass', values='Survived', aggfunc='mean')
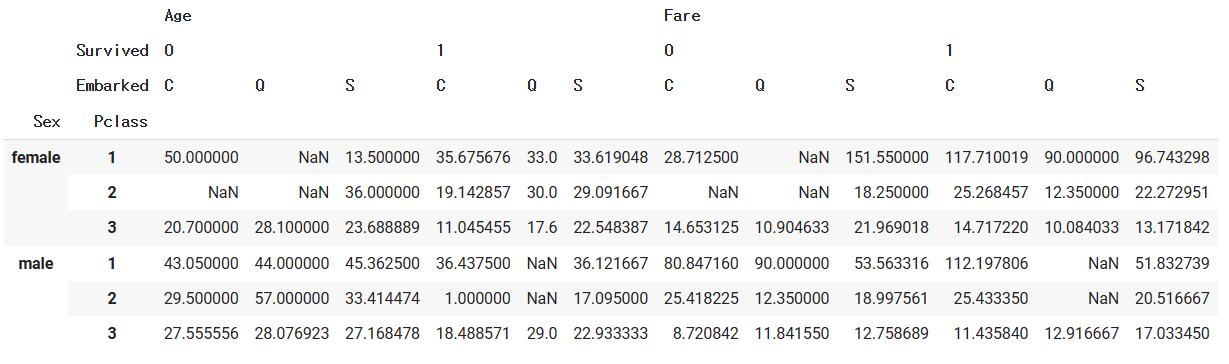
- 다중 인덱스, 다중 컬럼, 다중 값
# 성별과 객실등급을 다중인덱스로, 생존여부와 탑승지를 다중컬럼으로, 평균나이와 평균요금을 값으로 갖는 피벗테이블 생성pd.pivot_table(df, index=['Sex','Pclass'], columns=['Survived','Embarked'], values=['Age','Fare'], aggfunc='mean')
# 성별과 객실등급을 다중인덱스로 하고 요금과 생존여부의 평균, 중앙값, 합계를 값으로 갖는 피벗테이블 생성
pivot = pd.pivot_table(df, index=['Sex','Pclass'], values=['Survived','Fare'], aggfunc=['mean','median','sum'])

- stack
- 컬럼 레벨에서 인덱스 레벨로 피벗테이블을 변경
pivot.stack(0) # 컬럼의 첫번째 레벨('mean', 'median', 'sum')을 세번째 인덱스로 내림pivot.stack(1) # 컬럼의 두번째 레벨('fare', 'survived')을 세번째 인덱스로 내림
- 컬럼 레벨에서 인덱스 레벨로 피벗테이블을 변경
- unstack
- 인덱스 레벨에서 컬럼 레벨로 피벗테이블을 변경
- stack의 반대
pivot.unstack(0) # 인덱스의 첫번째 레벨('sex')을 세번째 컬럼으로 쌓아 올림pivot.unstack(1) # 인덱스의 첫번째 레벨('pclass')을 세번째 컬럼으로 쌓아 올림
- melt
- wide dataframe → long dataframe
- pd.melt(데이터명, id_vars=기준 컬럼)
data = pd.DataFrame({'name':['a','b','c'], 'order_count':[3,4,10], 'amount':[10000,25000,300000]})# 'name' 컬럼을 기준으로 다른 컬럼들의 값들을 나열## key들이 모인 컬럼(var_name)의 이름을 'type'으로, value들이 모인 컬럼(value_name)의 이름을 'val'로pd.melt(data, id_vars=['name'], var_name='type', value_name='val')

'패스트캠퍼스 데이터분석 부트캠프 14기 > 주차별 학습기록' 카테고리의 다른 글
| 패스트캠퍼스 데이터분석 부트캠프 8주차_SQL (1) (0) | 2024.06.14 |
|---|---|
| 패스트캠퍼스 데이터분석 부트캠프 5주차_PYTHON (3) (0) | 2024.05.24 |
| 패스트캠퍼스 데이터분석 부트캠프 3주차_PYTHON (1) (0) | 2024.05.10 |
| 패스트캠퍼스 데이터분석 부트캠프 2주차_EXCEL (2) (0) | 2024.05.03 |
| 패스트캠퍼스 데이터분석 부트캠프 1주차_빅데이터 이해와 데이터 리터러시 함양하기 & EXCEL (1) (1) | 2024.04.25 |
'패스트캠퍼스 데이터분석 부트캠프 14기/주차별 학습기록' Related Articles
more
