
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- 패스트캠퍼스
- 지금 우리 학교는
- 드라마
- 데이터분석부트캠프
- 데이터분석
- 미유엔토
- 대중문화
- 데이터분석취업
- 국비지원
- 현혹
- 미디어 콘텐츠
- BDA
- 부트캠프
- 대외활동 추천
- 이태원 클라쓰
- 미뮤엔토 에디터
- 딥러닝 스터디
- 패스트캠퍼스데이터분석부트캠프
- 정년이
- 재혼황후
- 이지스퍼블리싱
- 미뮤엔토
- 웹툰 원작
- 대외활동
- 딥러닝교과서
- 패스트캠퍼스부트캠프
- 데이터분석가
- DOIT!
- 유미의 세포들
- 국비지원취업
Archives
- Today
- Total
디지털 마케팅 LAB
패스트캠퍼스 데이터분석 부트캠프 12주차_ChatGPT를 활용한 데이터 분석 실습하기 본문
패스트캠퍼스 데이터분석 부트캠프 14기/주차별 학습기록
패스트캠퍼스 데이터분석 부트캠프 12주차_ChatGPT를 활용한 데이터 분석 실습하기
홍보하swu 2024. 7. 12. 13:22지난 주 SQL프로젝트를 끝내고 태블로 강의를 시작하기 전 3일동안 생성형 AI를 활용한 데이터 분석에 대한 강의를 들었다. 이번 강의를 맡아주신 박조은 강사님은 오늘코드의 유튜브 채널을 운영 중이시고, 네이버 부스트코스의 데이터 사이언스의 교슈자도 겸업하시고 계신다고 했다.
이번 수업은
- 1일차 : 생성형 AI 의 다양한 제품군과 개요, 생성형 AI를 통한 도서 목록 수집 개요
- 과제 : Perplexity를 활용하여 미리 yes24 서점 사이트 수집해 보기
- 어떤 prompt를 사용해야 할지
- 2일차 : Perplexity를 활용한 YES24 서점 사이트 IT 도서 목록 수집과 분석
- IT 서적 출판사 데이터 분석가라 가정하고 IT 도서 트랜드 확인해 보기
- 과제 : YES24 실습 내용을 바탕으로 amazon.com 서점 사이트를 분석해 보기
- 3일차 : 다양한 제품군을 활용한 리텐션과 RFM 분석과 보고서 작성
- Mermaid, Excalidraw 등의 제품 활용
이와 같이 진행되었다.
생성형 AI에는 다양한 응용 서비스들이 존재한다.
| ChatGPT | Claude | perplexity | gemini | Bing chat | Wrtn | AskUP | ClovaX | |
| 제공자 | OpenAI | Anthropic | perplexity | Microsoft | Wrtn Technologies | Upstage | NAVER | |
| 특징 | 유료 버전이 성능과 멀티모달 기능을 제공 | 무료 버전에서도 성능이 좋으나 일제한량이 적음 | Claude, GPT-4o 모델로 RAG를 활용하여 검색기반 최신정보 | 이미지 해석은 되나 생성은 안됨, 구글의 다양한 서비스와 통합하여 개인화된 서비스를 제공 | Bing image creator로 이미지 무료 생성, 웹 검색 및 정보 제공을 위해 사용 | 이미지 해석 및 생성, 프롬프트 허브 | OCR 성능이 좋음, 카카오톡 기반 손쉬운 이용 | 네이버 콘텐츠 활용 |
프롬프트 엔지니어링
방법 1. 명확하고 체계인 지시를 작성하기
- 여러분의 작업 관련 내용을 모르는 신입 사원에게 지시하듯, 명확하고 체계적으로 필요한 결과를 얘기해야한다.
그리고 텍스트의 어조를 어떻게 원하는지 명시하는 것도 도움이 된다.
일반적으로 긴 프롬프트가 모델에게 더 많은 명확성과 맥락을 제공하며, 이는 실제로 더 상세하고 관련있는 결과를 이끈다.- x 앨런 튜링에 대해 무언가 써주세요
- o 앨런 튜링의 과학적인 업적 및 역사적 역할에 대해 전문 과학 기자처럼 알려줘
- x 가장 큰 나라를 알려줘
- o 인구가 가장 많은 나라를 알려줘
- 구분 기호를 사용하여 입력 내용을 명확하게 표시해야한다.
문장에서 끊어야 할 부분에 대해서 명확하게 띄어쓰기, 쉼표, 마침표 등으로 의도한 단어를 구분해라.
동일한 말도 구분에 따라서 의미 차이가 큰 경우라면, 명확한 구분이 중요하다.- x 아버지가방에 들어가신다
- o 아버지가 방에 들어가신다
- 구조화된 출력 방식을 요청해라.
어떤 형식으로 표현되길 원하는지 구체적으로 알려줘야한다.- x 구구단을 출력해 줘
- o 구구단을 9×9 표형식으로 출력해 줘
- X 도서관 이용시간 일정을 작성해 줘
- O 도서관 이용시간 일정을 요일별로 표로 작성해 줘
- 조건을 충족하는지 확인해라.
알고 싶은 내용 중 일부에만 조건이 해당하는 경우 어떤 결과를 알고 싶은지 요청한다.- 미국, 러시아, 중국 중에 가장 나라 면적이 큰 국가를 알려주고, 그 국가가 역사적으로 어떤 면적의 변화가 있었는지 알려줘
- 원하는 작업의 성공적인 실행 예시를 제공해라.(“Few-shot” prompting)
원하는 답변에 대한 베스트 예제가 있다면, 그 내용을 알려주고 일관된 스타일의 응답을 요청할 수 있다.
당신의 임무는 일관된 스타일로 대답하는 것이다.- <어린이>: 인내심에 대해 가르쳐주세요.
- <할머니>: 가장 깊은 골짜기를 조각하는 강은
- 계곡을 깎아내는 강은 겸손한 샘에서 흐르고,
- 가장 웅장한 교향곡은 하나의 음에서 시작된단다.
- <어린이>: 회복탄력성에 대해 가르쳐 주세요.
——- (위 프롬프트 입력 후의 답변) ——-
회복탄력성은 폭풍우 속에서도 꿋꿋이 버티고 시간이 지날수록 더욱 강해지는 떡갈나무와 같단다.
회복탄력성은 인생의 도전이 우리를 쓰러뜨리려 할 때다시 일어설 수 있도록 도와주는 내면의 힘이지.
방법 2. AI 모델에게 생각할 시간을 주기
AI 모델에게 짧은 시간이나 적은 단어로 너무 복잡한 작업을 주면, 잘못된 추측을 할 가능성이 높다.
이러한 상황에서는 AI 모델에게 문제를 더 오래 생각하도록 (계산하는 노력을 더 하도록) 지시할 수 있다.
- 단계를 나눠서 요청하기
복잡한 과업의 경우, 세부적으로 필요한 단계를 나누어 정해서 알려준다.- 첫째, 세 개의 문단으로 ˿분된 텍스트를 한 문장으로 요약하세요.
- 둘째, 요약문을 프랑스어로 번역하세요.
- 셋째, 프랑스어 요약문에 있는 각 이름을 나열하세요.
- 모델이 스스로 해결책을 찾도록 지시하기
입력된 수학 풀이가 잘 못 되어 있더라도, AI 모델에게 자신만의 풀이를 찾아내고 입력되어있는 수학 풀이와 비교하도록 할 수 있다.- 당신의 임무는 학생의 수학 풀이가 정답인지 확인하는 것입니다.
문제를 해결하기 위해 다음 단계를 수행합니다:
– 먼저 문제에 대한 자신만의 해결책을 찾아냅니다.
– 그런 다음 자신의 솔루션을 학생의 솔루션과 비교합니다.
이 후 학생의 솔루션이 올바른지 평가합니다.
학생의 솔루션이 올바른지 문제를 직접 풀기 전에는 결정하지 마세요.
- 당신의 임무는 학생의 수학 풀이가 정답인지 확인하는 것입니다.
방법 3. Retrieval-Augmented Generation
- 아래 [검색결과]를 바탕으로 질문에 해당하는 내용과 매칭해서 답변을 작성해.
[검색결과] -- 시작 -
"실제 검색 결과를 여기에 넣기"
[검색결과] -- 끝
질문 : 연세대학교 도서관에 대해 설명
고객의 가치를 평가해야하는 이유?
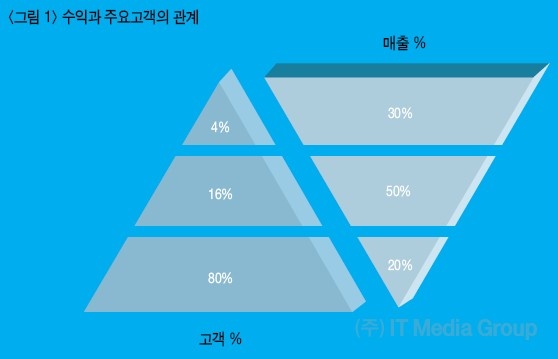
“기업의 첫 번째 과업은 고객창출이다.” 피터 드러커(Peter Drucker)
✔따라서 고객확보와 유지가 매우 중요!
✔모든 고객이 동일한 가치를 갖는가?
💡한정된 자원을 가지고 효율을 극대화하기위해 고객들의 가치를 평가하고, 차별화된 마케팅 전략 수립해야한다.
"상위 20%의 고객이 전체 매출의 80% 를 차지한다" 파레토 법칙(Pareto's law)
코호트, 잔존률 분석
- AARRR

- AARRR은 시장 진입 단계에 맞는 특정 지표를 기준으로 우리 서비스의 상태를 가늠할 수 있는 효율적인 기준
- 수많은 데이터 중 현 시점에서 가장 핵심적인 지표에 집중할 수 있게 함으로써, 분석할 리소스(인력이나 시간)가 충분하지 않은 스타트업에게 매력적인 프레임워크
– Acquisition: 어떻게 우리 서비스를 접하고 있는가
– Activation: 사용자가 처음 서비스를 이용할 때 긍정적인 경험을 제공하는가
– Retention: 이후의 서비스 재사용률은 어떻게 되는가
– Referral: 사용자가 자발적 바이럴, 공유를 일으키고 있는가
– Revenue: 최종 목적(매출)으로 연결되고 있는가
- 코호트 분석
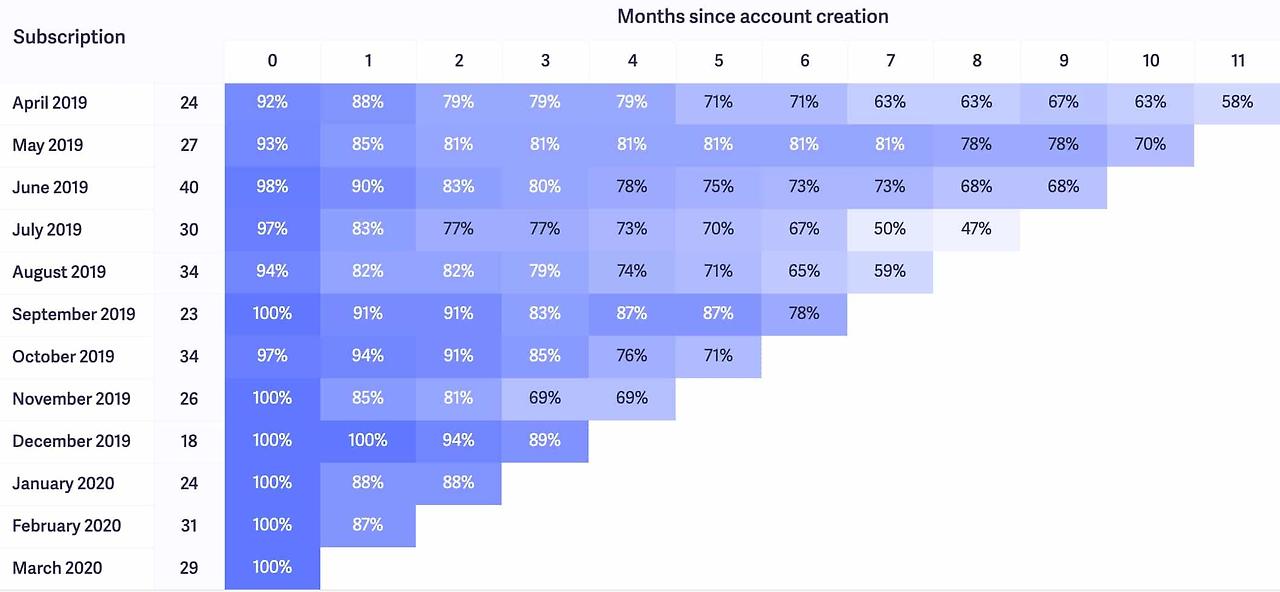
- 코호트 분석은 분석 전에 데이터 세트 의 데이터를 관련 그룹으로 나누는 일종의 행동 분석
- 이러한 그룹 또는 집단은 일반적으로 정의된 시간 범위 내에서 공통된 특성이나 경험을 공유
- 코호트 분석을 통해 회사는 고객이 겪는 자연적 주기를 고려하지 않고 맹목적으로 모든 고객을 분할하는 대신 고객(또는 사용자)의 수명 주기 전반에 걸쳐 패턴을 명확하게 볼 수 있음
- 이러한 시간 패턴을 보고 회사는 특정 집단에 맞게 서비스를 조정 가능
- 코호트 분석의 유형
– 시간집단: 시간 집단은 특정 기간 동안 제품이나 서비스에 가입 고객입니다. 이러한 집단을 분석하면 고객이 회사의 제품이나 서비스를 사용하기 시작한 시점을 기준으로 고객의 행동이 나타납니다. 시간은 월별 또는 분기별 또는 매일일 수 있습니다.
– 행동집단: 행동 집단은 과거에 제품을 구매했거나 서비스에 가입한 고객입니다. 가입한 제품 또는 서비스 유형에 따라 고객을 그룹화합니다. 기본 서비스에 가입한 고객은 고급 서비스에 가입한 고객과 요구 사항이 다를 수 있습니다. 다양한 코호트의 요구 사항을 이해하면 비즈니스에서 특정 세그먼트에 대한 맞춤형 서비스 또는 제품을 설계하는 데 도움이 될 수 있습니다.
– 규모집단: 규모 집단은 회사의 제품이나 서비스를 구매하는 다양한 규모의 고객을 나타냅니다. 이 분류는 획득 후 특정 기간의 지출 금액 또는 고객이 주어진 기간 동안 주문 금액의 대부분을 지출한 제품 유형을 기반으로 할 수 있습니다.
- 잔존율 분석
- 리텐션 분석은 고객이 이탈하는 방법과 이유를 이해하기 위해 사용자 메트릭을 분석하는 과정
- 유저 분석은 유지 및 신규 사용자 확보율을 개선하여 수익성 있는 고객 기반을 유지하는 방법 확보
- 일관된 유지 분석을 실행하여 알 수 있는 항목
– 고객이 이탈하는 이유
– 고객이 떠날 가능성이 더 높을 때
– 이탈이 수익에 미치는 영향
– 유지 전략을 개선하는 방법 - 투자자 입장에서 리텐션은 투자대박 가능성과 위험도를 동시에 볼 수 있는 지표이기 때문에 좋아할 수 밖에 없다. 스타트업에서의 투자에서, 리텐션이 높으면 신규 유저가 늘수록 누적되어 엄청나게 성과가 올라가기 때문에 특히 중요하게 생각한다. 반대로도 신규유저가 잠시 주춤하더라고, 그 회사가 계속 생존할 수 있다는 안정성을 입증하는 지표이기도 하기 때문에 리텐션을 잘 보여주는 자료나 그래프를 잘 만들면 좋다.
RFM 분석
- RFM은 가치있는 고객을 추출해내어 이를 기준으로 고객을 분류할 수 있는 분석 방법
- 구매 가능성이 높은 고객을 선정하기 위한 데이터 분석방법
- 세가지 지표 또는 차원에 따라 각 고객을 분석
- Recency - 거래의 최근성: 고객이 얼마나 최근에 구입했는가?
- Frequency - 거래빈도: 고객이 얼마나 빈번하게 우리 상품을 구입했나?
- Monetary - 거래규모: 고객이 구입했던 총 금액은 어느 정도인가?
- 가장 큰 과제는 그룹의 경계를 정의하는 것
- 고객 세분화의 항목
- 판매정보: 상품판매 자료 거래 금액, 횟수
- 인구통계학적 정보: 나이, 성별, 직업, 학력,거주지역, 소득수준
- 라이프스타일 정보: 순차적, 구매 정보, RFM 정보
- 심리 정보: 구매욕구
- 행동 정보: 구매패턴 Life Time Value
💡구매 행동별로 고객을 묶어 각 고객집단별로 차별화된 마케팅 전략을 수립
- 판매정보: 상품판매 자료 거래 금액, 횟수
- 고객 세분화의 예시
- 한 기업에서 RFM에 의하여 고객을 분류한 후에 각 고객들에게 DM을 발송하고 측정한 각 집단별 이익 수준을 구했을 때,
- 가장 많은 이익을 가져다주는 집단은?
- 손해를 주는 집단의 특징은?
- 각 집단별 서열화는 어떻게 할것인가?(등급)
💡RFM 모형 분석에서는 이와 같이 제 2의 분석을 통하여 각 집단의 중요도를 측정하고 그 결과를 미래의 마케팅에 활용하는 것이 RFM 모형의 목적
- Online Retail의 RFM
- Recency: 최근 구매일 (구매일 - x.max()).days) → 최근일수록 높은 스코어
- Frequency: 구매 빈도수(count)
- Monetary: 총 구매금액(sum)
💡RFM_score을 기준으로 고객등급 설정
ex) Silver, gold, platinum
'패스트캠퍼스 데이터분석 부트캠프 14기 > 주차별 학습기록' 카테고리의 다른 글
| 패스트캠퍼스 데이터분석 부트캠프 13주차_Tableau (1) (0) | 2024.07.19 |
|---|---|
| 패스트캠퍼스 데이터분석 부트캠프 9주차_SQL (2) (0) | 2024.06.21 |
| 패스트캠퍼스 데이터분석 부트캠프 8주차_SQL (1) (0) | 2024.06.14 |
| 패스트캠퍼스 데이터분석 부트캠프 5주차_PYTHON (3) (0) | 2024.05.24 |
| 패스트캠퍼스 데이터분석 부트캠프 4주차_PYTHON (2) (0) | 2024.05.17 |
'패스트캠퍼스 데이터분석 부트캠프 14기/주차별 학습기록' Related Articles
more
